

本篇主要介绍Python的数据结构如下:
1、数字类型
2、字符串
3、列表
4、元组
5、字典
6、集合
一、数字类型
1.bin()函数将十进制转换成而进制
2.oct()函数将十进制转换成八进制
3.hex()函数将十进制转换成十六进制
十六进制表示:0-9 a b c d e f
4.数字类型的特性:
只能存放一个值
一经定义,不可更改
直接访问
分类:整型,布尔,浮点,复数
5.字符串类型
引号包含的都是字符串类型
S1='hello world' s="hello world"
s2="""hello world"""
s3='''hello world'''
单引双引没有区别
6.字符串的常用操作
- strip()移除空白,也可以去除其他的字符
-
slipt()分割,默认以空格分割。也可以以其他的字符分割
-
len()长度 切片:如print(x[1:3])也是顾头不顾尾
print(x[0:5:2])#0 2 4
- capitalize()首字母大写
-
center()居中显示例如:x='hello' print(x.center(30,'#'))
>>> x='hello'
>>> print (x.center(30,'#'))
############hello#############
-
count():计数,顾头不顾尾,统计某个字符的个数,空格也算一个字符
-
endswith()以什么结尾
-
satrtswith()以什么开头
-
find()查找字符的索引位置,如果是负数,代表查找失败
-
index()索引
find() 和 index() 的区别,如下测试:
>>> s='hello' ##s赋值为hello字符串
>>> s.find('o') #查找o所在字符串的位置(从0开始)
4
>>> s.index('o')
4
>>> s.find('a') #当a不存在的是否,就输出负数
-1
>>> s.index('a') #但是用index查找不到,就直接报错了
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
ValueError: substring not found
>>>
format()字符串格式化
1.msg='name:{},age:{},sex:{}'
print(msg.format('qiuyuetao','18','男'))
结果:name:qiuyuetao,age:18,sex:男
2.msg='name:{0},age:{1},sex:{0}'
print(msg.format('aaaaaa','bbbbbb'))
结果:name:aaaaaa,age:bbbbbb,sex:aaaaaa
3.msg='name:{x},age:{y},sex:{z}'
print(msg.format(x='wuchen',y='18',z='女'))
结果:name:wuchen,age:18,sex:女
- isdigit()判断是否是数字
-
islower()判断是否是全部小写
-
isupper()判断是否是全部大写
-
lower()全部转换为小写
-
upper()全部转换为大写
-
isspace()判断是否是全都是空格
-
istitle()判断是否是标题(首字母大写)
-
swapcase()大小写字母翻转
-
join()连接
info='root:x:0:0::/root:/bin/bash'
print(info.split(':'))
join的反向用法
l=['root', 'x', '0', '0', '', '/root', '/bin/bash']
print(':'.join(l))
- repalce()替换
>>> msg='hello alex alex'
>>> print (msg.replace ("alex","qiuyuetao",1))
hello qiuyuetao alex
>>> print (msg.replace ("alex","qiuyuetao",2))
hello qiuyuetao qiuyuetao
- ljust()左对齐
>>> X='ABC'
>>> print(X.ljust(10,'*'))
ABC*******
二、字符串
2.1 %s,%d
例1:
name='egon'
age=20
print("my name is %s my age is %s" %(name,age))
print('my name is %s my age is %d' %(name,age))
##%s既能接受字符串,也能接受数字
##%d只能接受数字
例2:用户信息的显示
while True:
name=input("name:")
age=input("age:")
sex=input("sex:")
height=input("height:")
msg='''
------------%s info-----------
name:%s
age:%s
sex:%s
height:%s
------------------------------
'''%(name,name,age,sex,height)
print(msg)
2.2 字符串方法
查看输出类型
name='egon' #name=str('egon')
print(type(name))
#str 表示字符串类型
2.3 优先掌握内容
- strip移除空白,也可以去除其他的字符
msg = ' hello '
print(msg)
print(msg.strip())
移除*
msg='***hello*********'
print(msg)
msg=msg.strip('*')
print(msg)
msg='***hello*********'
print(msg.lstrip('*')) #移除左边
print(msg.rstrip('*')) #移除右边
使用案例
while True:
name=input('user: ').strip()
password=input('password: ').strip()
if name == 'egon' and password == '123':
print('login successfull')
- 切分split
info='root:x:0:0::/root:/bin/bash'
print(info[0]+info[1]+info[2]+info[3])
print(info[0]+info[1])
user_l=info.split(':')
print(user_l[0])
msg='My name is qiuyuetao haha'
print(msg.split()) #默认以空格作为分隔符
cmd='download|xhp.mov|3000'
cmd_l=cmd.split('|')
print(cmd_l[1])
print(cmd_l[0])
print(cmd.split('|',1))
使用案例
while True:
cmd=input('>>: ').strip()
if len(cmd) == 0:continue #如果字符串长度是0 就跳出循环
cmd_l=cmd.split()
print('命令是:%s 命令的参数是:%s' %(cmd_l[0],cmd_l[1]))
------------
#len 长度
print(len('hello 123'))
结果:9 #把引号的内容占位算做长度,包含空格
------------
#索引
# 切片:切出子字符串
msg='hello world'
print(msg[1:3]) #1 2
print(msg[1:4]) #1 2 3
结果:
el
ell
2.4 掌握部分
- 判断字符串是否为整数
while True:
age=input('>>: ').strip()
if len(age) == 0:
continue
if age.isdigit():
age=int(age)
else:
print('must be int')
2. startswith(以..开头),endswith(以..结尾)
name='alex_SB'
print(name.endswith('SB')) #判断字符串是否已‘SB’结尾,如果是返回True
print(name.startswith('alex')) #判断字符串是否以‘alex’结尾,如果是返回True
- replace 字符串 新旧替换
name='qiuyt say :i have one tesla,my name is qiuyt'
print(name.replace('qiuyt','baba',1))
#把qiuyt,更改为baba,修改1次
4,字符串传参案例
print('my name is %s my age is %s my sex is %s' %('egon',18,'male'))
print('my name is {} my age is {} my sex is {}'.format('egon',18,'male'))
print('my name is {0} my age is {1} my sex is {0}:{2}'.format('egon',18,'male'))
print('my name is {name} my age is {age} my sex is {sex}'.format(
sex='male',
age=18,
name='egon'))
5,lower,upper
name='QiuYueTao'
print(name.lower())
结果:qiuyuetao #把大写变为小写
print(name.upper())
结果:QIUYUETAO #把小写变为大写
2.5 了解部分
#expandtabs
Python expandtabs()方法把字符串中的tab符号('\ t')转为空格,tab符号('\ t')默认的空格数是8。
name='egon\thello'
print(name)
print(name.expandtabs(1))
#center,ljust,rjust,zfill
name='egon'
# print(name.center(30,'-'))
print(name.ljust(30,'*'))
print(name.rjust(30,'*'))
print(name.zfill(50)) #用0填充
#swapcase() 方法用于对字符串的大小写字母进行转换。
#title() 方法返回"标题化"的字符串,就是说所有单词的首个字母转化为大写,其余字母均为小写
name='eGon'
print(name.capitalize()) #首字母大写,其余部分小写
print(name.swapcase()) #大小写翻转
msg='egon say hi'
print(msg.title()) #每个单词的首字母大写
#在python3中 实例说明
num0='4'
num1=b'4' #bytes
num2=u'4' #unicode,python3中无需加u就是unicode
num3='四' #中文数字
num4='Ⅳ' #罗马数字
# isdigt:str,bytes,unicode
print(num0.isdigit())
print(num1.isdigit())
print(num2.isdigit())
print(num3.isdigit())
print(num4.isdigit())
------------
# isdecimal:str,unicode
num0='4'
num1=b'4' #bytes
num2=u'4' #unicode,python3中无需加u就是unicode
num3='四' #中文数字
num4='Ⅳ' #罗马数字
print(num0.isdecimal())
# print(num1.)
print(num2.isdecimal())
print(num3.isdecimal())
print(num4.isdecimal())
------------
#isnumeric:str,unicode,中文,罗马
num0='4'
num1=b'4' #bytes
num2=u'4' #unicode,python3中无需加u就是unicode
num3='四' #中文数字
num4='Ⅳ' #罗马数字
print(num0.isnumeric())
# print(num1)
print(num2.isnumeric())
print(num3.isnumeric())
print(num4.isnumeric())
------------
# is其他
name='egon123'
print(name.isalnum()) #判断字符串由字母和数字组成
结果:"True"
name='asdfasdfa sdf'
print(name.isalpha()) #判断字符串只由字母组成
结果:"False"
name = 'qiuyuetao'
print(name.islower()) #判断字符串全部是小写
结果:"True"
name = 'Qyt'
print(name.istitle()) #判断字符串首字母大写
结果:"True"
三、列表
1、列表简介
序列是Python中最基本的数据结构。
Python有6个序列的内置类型,但最常见的是列表和元组。
列表是最常用的Python数据类型,它可以作为一个方括号内的 逗号分隔值出现。
作用:多个装备,多个爱好,多门课程,多个女朋友等
定义:[ ] 内可以有多个任意类型的值,逗号分隔<<
创建一个列表,只要把逗号分隔的不同的数据项使用方括号括起来即可。如下所示:
list1 = ['physics', 'chemistry', 1997, 2000]
list2 = [1, 2, 3, 4, 5 ]
list3 = ["a", "b", "c", "d"]
2、列表的常用操作:
# 查看字符类型
l=[1,2,3] #l=list([1,2,3])
print(type(l))
结果:"<class 'list'>"
3、优先掌握(重要)
l=['a','b','c','d','e','f']
print(l[0],l[1],l[2],l[3],l[4],l[5])
print(l[1:3]) #顾头不顾尾{切片}
print(l[1:5:2]) #去1-4,步长为2:隔-1步,
print(l[2:5])
print(l[-1]) #取最后1个字符,倒数第2个 就是-2
4、追加\长度\判断\删除、
##追加
hobbies=['play','eat','sleep','study']
hobbies.append('girls') #默认加到最后
print(hobbies)
结果:['play', 'eat', 'sleep', 'study', 'girls']
------------
##删除
hobbies=['play','eat','sleep','study']
x=hobbies.pop(1) #不是单纯的删除,是删除并且把删除的元素返回给我,我们可以用一个变量名去接收该返回值
print(x)
print(hobbies)
结果:eat
['play', 'sleep', 'study']
remove #是单纯删除,不会返回值,并且可以直接删除指定值
pop #按照索引去删,默认是从末尾去少【索引0-1-2-3】
del hobbies[1] #单纯的删除
------------
## 长度
print(len(hobbies)) #统计列表已 逗号分割 有几个元素
结果:5
------------
## 判断
print('eat' in hobbies)
结果:True
------------
5、常用操作
5.1 在指定位置insert插入
###########################
hobbies=['play','eat','sleep','study','eat','eat']
# hobbies.insert(0,'qiuyuetao')
hobbies.insert(2,'baba') #在索引2前面插入baba
print(hobbies)
结果:['play', 'eat', 'baba', 'sleep', 'study', 'eat', 'eat']
# hobbies.insert(1,['walk1','walk2','walk3']) #一次插入多个值,但在一个索引内
# print(hobbies)
####################
5.2 conunt 统计个数
####################
hobbies.insert(1,'qiuyuetao') #在索引1前,插入qiuyuetao
print(hobbies)
print(hobbies.count('qiuyuetao')) #统计qiuyuetao出现的次数
print(hobbies.count('eat')) ##统计eat 出现过多少次
结果:
['play', 'qiuyuetao', 'eat', 'sleep', 'study', 'eat', 'eat']
1
3
####################
5.3 extend 添加多个值
####################
hobbies.extend(['walk1','walk2','walk3']) #添加多个值,到最后
print(hobbies)
结果:
['play', 'eat', 'sleep', 'study', 'eat', 'eat', 'walk1', 'walk2', 'walk3']
#了解
# print(l[-1:-4])
# print(l[-4:])
# l=['a','b','c','d','e','f']
# print(l[-2:])
##sort 排序
l=[1,2,3,4,5] #正序排列
l.reverse()
print(l)
l=[100,9,-2,11,32] #倒序排列
l.sort(reverse=True)
print(l)
#队列:先进先出[像我生活中的扶梯]
queue_l=[]
#入队
# queue_l.append('first') #第一个输入的,显示就排在第一个
# queue_l.append('second')
# queue_l.append('third')
# print(queue_l)
#出队
# print(queue_l.pop(0)) #先进去先出来
# print(queue_l.pop(0))
# print(queue_l.pop(0))
#堆栈:先进后出,后进先出
# l=[] #空列表
# #入栈
# l.append('first') #用append 添加值进去
# l.append('second')
# l.append('third')
# #出栈
# print(l)
# print(l.pop()) #默认就是-1
# print(l.pop())
# print(l.pop())
列表总结:
- 可以存多个值、可以是任一类型
- 按照索引的方式,进行有序的排列
- 可变类型,在原来基础之上,还能进行修改,才叫可变类型
四、元组
查看类型
t=(1,[1,3],'sss',(1,2)) #t=tuple((1,[1,3],'sss',(1,2)))
print(type(t))
- 为何要有元组,存放多个值,更多的是用来做查询
- 与列表不同之处:列表可以改变,但元组是不可变的
4.1 优先掌握
# goods=('iphone','lenovo','sanxing','suoyi')
# print(goods.index('iphone')) #查看某1个元素的索引,不存在就报错
# print(goods.count('iphone')) # 统一某一个元素的格式,比如iphone有几个
结果:
0 iphone在元组里索引是0
1 iphone在元组里只有1个
#补充:元组本身是不可变的,但是内部的元素可以是可变类型
#t=(1,['a','b'],'sss',(1,2)) #t=tuple((1,[1,3],'sss',(1,2)))
# t[1][0]='A'
# print(t)
## 产生新的元组,并没有改变原来元组
ages=(11,12,33,24)
print(ages[0:2]) # 按照索引索取,是新建,不改变原有元组
print(ages)
4.2其它内容与列表类似
# #元组可以作为字典的key
# d={(1,2,3):'egon'}
# print(d,type(d),d[(1,2,3)])
# 切片
# goods=('iphone','lenovo','sanxing','suoyi')
# print(goods[1:3])
# 长度
print(len(ages))
#in:
print(11 in ages)
#字符串:子字符串
#列表:元素
#元组:元素
#字典:key
# goods=('iphone','lenovo','sanxing','suoyi')
# print('iphone' in goods)看的是里面的元素在不在里面
# d={'a':1,'b':2,'c':3}
# print('b' in d) 看的是key在不在d里面
逗哥练一练---
简单购物车,实践:
while循环
w=['邱月涛','大宸宸']
q=0
while q < len(w):
print(w[q]) #想办法把索引取名字print(w[0:2])
q+=1
for循环
五、字典
字典常用的方法
info_dic={'name':'qiuyuetao','age':18,'sex':'male'}
数字类型、字符串、元组 都属于不可变类型。
定义:key必须是不可变类型,value可以是任意类型
字典的每个键值 key=>value对用冒号 :分割,每个键值对之间用逗号 , 分割,整个字典包括在花括号 {} 中 ,格式如下所示:
d = {key1 : value1, key2 : value2 }
字典的内置方法及描述
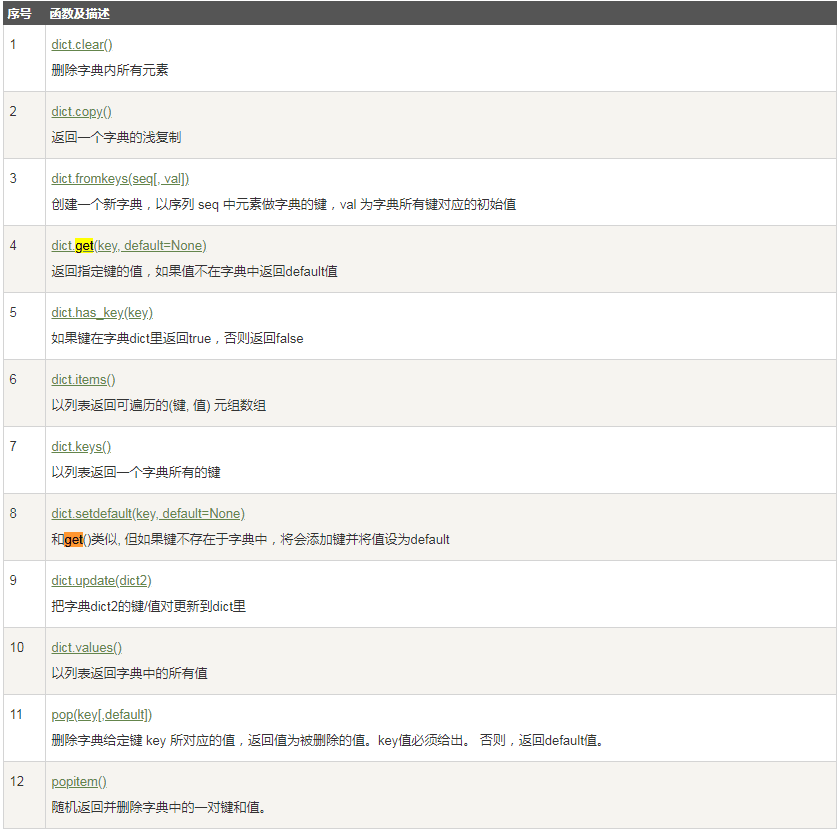
常用操作:
1,存取
info_dic = {'name':'egon','age':18,'sex':'male'}
print(info_dic['name'])
结果: egon
# print(info_dic['name11111']) #找不到则报错了
print(info_dic.get('name1111',None))
#get方法找不到不报错,可以自己设定默认值,如果不设置可以写None
结果:None
------------
pop:key存在则弹出值,不存在则返回默认值,如果没有默认值则报错
info_dic = {'name':'egon','age':18,'sex':'male'}
print(info_dic.pop('name',None))
print(info_dic)
结果:egon #name存在,就打印了次key的vl
{'age': 18, 'sex': 'male'} #在打印就不显了
print(info_dic.pop('qiuyuetao','None')) #key不存在
print(info_dic)
结果:None #就返回默认值None
{'age': 18, 'sex': 'male'} #打印上面info_dic
print(info_dic.popitem()) #popitem popitem随机返回并删除字典中的一对键和值,虽然看着像最后,但字段是无序的。
print(info_dic)
结果:('sex', 'male')
{'name': 'egon', 'age': 18}
info_dic['level']=10 #插入键值对key level vl 10
print(info_dic)
结果:{'name': 'egon', 'age': 18, 'level': 10}
2,删除
能删单一的元素也能清空字典,清空只需一项操作。
显示删除一个字典用del命令,如下实例:
dict = {'Name': 'qiuyuetao', 'Age': 7, 'url': 'dgstack.cn'}
del dict['Name'] # 删除键 'Name'
# dict.clear() # 清空字典
# del dict # 删除字典
print ("dict['Age']: ", dict['Age'])
print ("dict['url']: ", dict['url'])
但这会引发一个异常,因为用执行 del 操作后字典不再存在:
3,显示字典key+values
info_dic={'name':'egon','age':18,'sex':'male'}
print(info_dic.keys()) ##显示字典内所有key
print(info_dic.values()) ## 显示字典内所欲values
print(info_dic.items()) ## 显示key+values
4,修改字典
向字典添加新内容的方法是增加新的键/值对,修改或删除已有键/值对如下实例:
dict = {'Name': 'qiuyuetao', 'Age': 7, 'url': 'dgstack.cn'}
print("dict['Age']:",dict['Age'])
print("dict['url']:",dict['url'])
print("上面是修改前,下面是修改后")
dict['Age']='8' #将age由7更新为8
dict['url']='www.dgstack.cn'
print("dict['Age']:",dict['Age'])
print("dict['url']:",dict['url'])
其它操作
len长度
print(len(dict)) #查看字典key+vlanle 组合数
包含in not in
print('url' in dict) #字段中是否包含该字段url
(copy) 将dict字段copy到d,然后将dict清空
dict = {'Name': 'qiuyuetao', 'Age': 7, 'url': 'dgstack.cn'}
d=dict.copy()
print(d)
dict.clear()
print(dict)
六、集合
集合(set)是一个无序的不重复元素序列。
可以使用大括号{ } 或者 set() 函数创建集合,注意:创建一个空集合必须用 set() 而不是 { },因为{ } 是用来创建一个空字典。
创建格式:
parame = {value01,value02,...}
或者
set(value)
1,去重、判断
basket = {'apple', 'orange', 'apple', 'pear', 'orange', 'banana'}
print(basket) # 这里演示的是去重功能
#结果:{'apple', 'banana', 'pear', 'orange'}
print('orange' in basket) # 快速判断元素是否在集合内
#结果:True
print('crabgrass' in basket)
#结果:False
2,下面展示两个集合间的运算
a = set('qiuyuetao123')
b = set('qiuyuetao')
print(a) #打印无序且内容不重复
print(a-b) #集合a中包含元素
print(a|b) # 集合a或b中包含的所有元素
print(a&b) #集合a和b 相同的部分
print(a^b) #集合a和b 不同的部分
类似列表推导式,同样集合支持集合推导式(Set comprehension):
a = {x for x in 'abracadabra' if x not in 'abc'}
print(a)
#结果:{'r', 'd'}
3. 添加元素
语法格式如下:
s.add( x )
将元素 x 添加到集合 s 中,如果元素已存在,则不进行任何操作。
thisset = set(("Google", "Runoob", "Taobao"))
thisset.add("Facebook")
print(thisset)
#结果: {'Taobao', 'Facebook', 'Google', 'Runoob'}
还有一个方法,也可以添加元素,且参数可以是列表,元组,字典等,语法格式如下:
s.update( x )
x可以有多个,用逗哥分开
thisset = set(("Google", "Runoob", "Taobao"))
thisset.update({1,3})
print(thisset)
#结果:{'Runoob', 1, 3, 'Taobao', 'Google'}
thisset.update([1,2],[3,4])
print(thisset)
#结果:{'Runoob', 1, 3, 2, 4, 'Taobao', 'Google'} 因为不打印重复项,所以1只出现1次
4.移除元素
语法格式如下:
s.remove( x )
将元素 x 从集合 s 中移除,如果元素不存在,则会发生错误。
thisset = set(("Google", "Runoob", "Taobao"))
thisset.remove('Google')
print(thisset)
#结果:{'Taobao', 'Runoob'}
thisset.remove('qiuyuetao')
print(thisset)
#结果: 不存在会发生错误
此外还有一个方法也是移除集合中的元素,且如果元素不存在,不会发生错误。格式如下所示:
s.discard( x )
thisset = set(("Google", "Runoob", "Taobao"))
thisset.discard('Taobao')
print(thisset)
# 结果:{'Google', 'Runoob'}
随机删除
s.pop()
thisset = set(("Google", "Runoob", "Taobao"))
thisset.pop()
print(thisset)
#结果:随机删除1个,显示另外2个
5.计算集合元素个数(长度)
#len(s)
thisset = set(("qiuyuetao", "Runoob", "Taobao"))
print(len(thisset))
#结果:3
6.判断元素是否在集合中存在
语法格式如下:
x in s
判断元素 x 是否在集合 s 中,存在返回 True,不存在返回 False。
thisset = set(("qiuyuetao", "Runoob", "Taobao"))
print("qiuyuetao" in thisset)
#结果:True
print("abc" in thisset)
#结果:False
- QQ精品交流群
-

- 微信公众号
-





2018年11月14日 下午10:47 沙发
不错👍一起学习,坚持住
2018年11月15日 下午2:22 1层
@汉化i 谢谢支持。